

Data: the 21st century’s most valuable resource. But do we really know how to read and comprehend it? Or do we know the way to gather, process, and analyze mass data to make it useful? And useful is the keyword here.
This article is based on an internal project carried out by our team of data scientists, machine learning researchers, and R&D software engineers, who analyzed medical articles from various sources in real time. We don’t want to focus on the project itself, but we will delve into details of big data tools and technologies they used, such as machine learning libraries, monitoring tools, and data management software.
You will also learn more about Spark, MLib, Spark NLP, Kubernetes and its six distributions, Prometheus, Grafana, and Cassandra. There’s a lot to cover here, so without further ado, let’s get started!
What is big data?
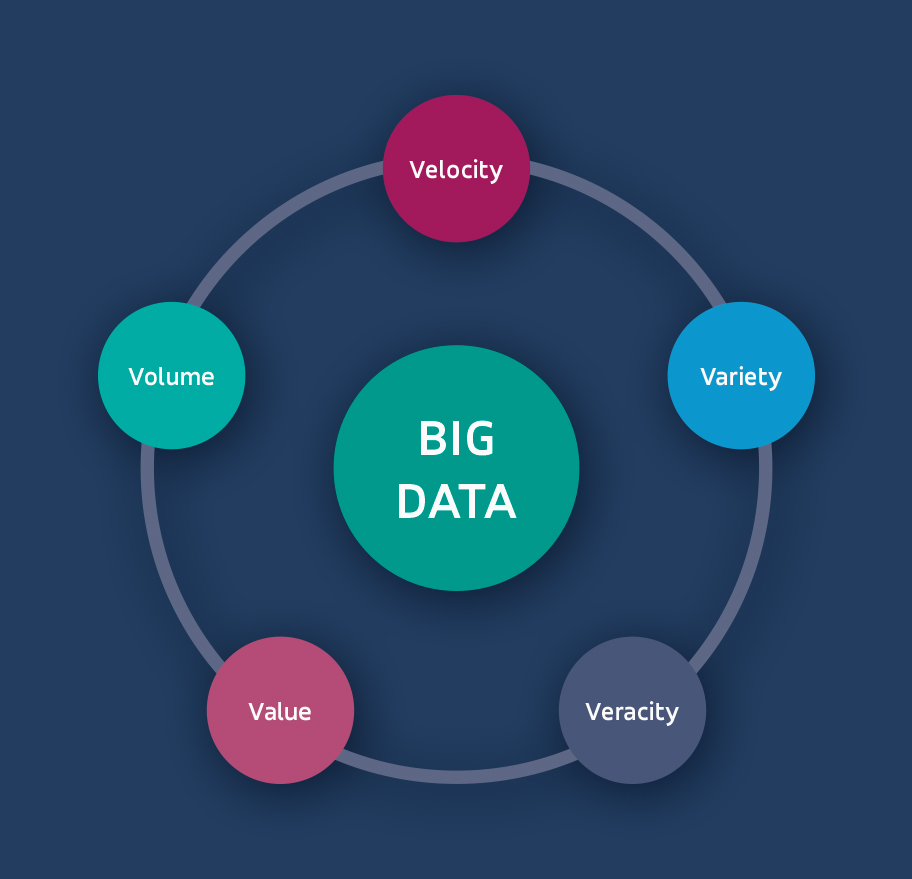
First, it would be a good idea to go back to the roots, defining what big data is because we need to be able to differentiate it from the standard data we gather. A 5V model explains it in a straightforward way.
Big data can be characterized by the following:
huge volume: we gather hundreds of terabytes or petabytes
high velocity: data flow and analysis take place at great speed
data variety: we collect multimodal data (numerical, text, audio, and video), that can be structured and unstructured
veracity: data is accurate and can be validated
business value: there’s a practical purpose to collecting and analyzing given information
The first three are the must-have criteria; without meeting them, we can’t say data is big.
From data silos to data lakes
In business reality, big data is commonly used in the context of analytical pipelines that gather and examine data for the purpose of business intelligence.
Even within a single company, analytical systems are often created independently – in different branches, countries, and at different times. Thus, they frequently turn out to be incompatible and challenging or even impossible to integrate. This situation is called data silos.
In response to problems generated by the above mentioned phenomenon, a new, high-level approach has emerged: data lakes. According to this technique, we gather all data in one place, regardless if the records are structured or not. Furthermore, we assume that all pipelines will have independent ETLs (extract-transform-load), so they’ll be able to pick whatever they need from the data lake. Unlike data silos, the lakes allow for easy pipeline integration, support data mining, and prepare us for future data application that might be hard to predict at a given moment.
How to process big data?
To make use of big data, we need to collect it and make calculations with it. We perform both activities in a distributed manner.
For storage, we use distributed file systems like HDFS (Hadoop Distributed File System) and databases like Apache Cassandra that support scalability and integrity between the nodes.
We carry out distributed computing on computing clusters. To manage distributed calculations, we usually use algorithms like MapReduce and frameworks like Hadoop or, more often, Apache Spark.
Big data analytics tools: A summary
It wouldn’t be possible to go through all tools for big data analytics in one blog post. Thus, we will focus on the ones we used in the project that classified medical publications. Here they are:
Apache Spark: a multi-language big data analysis engine
Apache Kafka: a distributed event streaming platform and data pipeline source
MLlib, Spark NLP: libraries used for machine learning, both compatible with Spark
Apache Cassandra: a distributed database
Kubernetes: a big data software for orchestration and dockerization
Prometheus: monitoring and alerting toolkit for Kubernetes
Grafana: a visualization system that uses data from Prometheus
In the next part of the article, we explain how the above tools work.
The pipeline
Below, you can see the pipeline we’ve implemented:
First, the data simulators feed Kafka, the event streaming platform, and the static database (Mongo) that Spark reads from
In the Spark stream, there are a few stages of data processing; the first one being text and feature extraction
Then, depending on the version, we use one or more ML models, e.g., for named entity recognition, embeddings calculation, classification based on embeddings (MLlib trained in this particular case)
The results are sent to Cassandra and predictions are sent back to Kafka
Based on the above, we can update the results in Prometheus and the dashboard in Grafana

How to analyze big data: Apache Spark
Apache Spark is a widely-used engine for data analysis and processing and executing machine learning models on clusters. It goes well with programming languages like Python, Scala, SQL, Java, and R, and integrates with various frameworks, providing high system scalability. These include tools we commonly use in our projects, such as TensorFlow, PyTorch, mongoDB, Kubernetes, and Elasticsearch. What’s essential, Spark works on structured and unstructured data.
A driver program that executes parallel operations on a cluster is essential to Spark applications. A group of elements partitioned across the cluster is called a resilient distributed dataset (RDD); we will use the term often in the rest of the article.
Structured Streaming in Spark: How does it work?
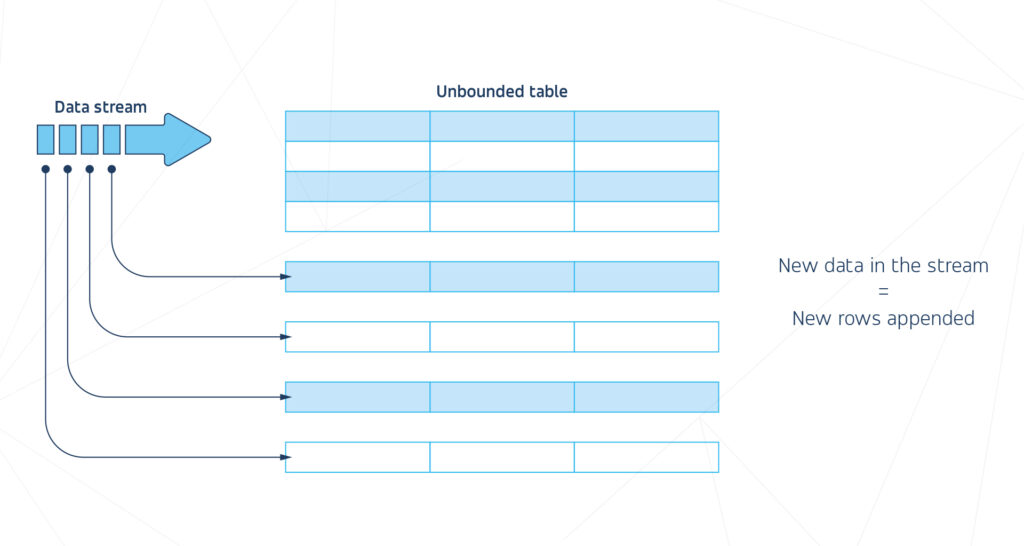
RDDs are static, which means their content doesn’t change while we execute operations. Thus, we need a tool to work on continuous data streams. For this purpose, we use Structured Streaming, a Spark processing engine that updates the computation results as streaming data arrives. Together with Continuous Processing, end-to-end latencies can be as low as 1 ms.
The idea is to consider a data stream as a simple, unbounded table that changes with time. We can run the same operations on this table as we do on an RDD: aggregate and filter data, define functions to calculate column values, and join with RDDs. Stream-specific operations are also possible, such as windowed aggregations or joining streams.
Spark allows us to view data streams and send them to the external data source in three ways:
Append: we send only the new rows; it’s a default mode
Complete: we send all table rows
Update: we send only the rows that have been updated
How does it work under the hood? First, we use the existing RDD machinery, so every stream is divided into small batches (static micro RDD tables). Then, Spark performs operations on them, and finally, they are converted back to one stream. A slight latency may occur in the process; however, a new experimental method also allows for proper real-time mode.
Data sources and sinks
When it comes to data sources, there aren’t many of them built in Spark. The existing ones include the following:
Kafka
Sockets
Files
However if you plan to use other data sources, you’ll find relevant Spark plugins for most of them.
Spark Machine Learning Library (MLlib) and Spark NLP
When discussing tools for big data analytics, we cannot fail to mention Spark MLlib. We use it, as the name suggests, for machine learning. It is a highly convenient tool for simpler models, like classification, regression, clustering, decision trees, and recommender systems.
However, the drawback is, we can’t use it with our own models, so we have to utilize an additional library like Spark NLP or Spark Deep Learning. For article classification, we use modern language models based on transformers like RoBERTa. On the other hand, Spark Deep Learning supports deep convolutional networks handy in, for example, Computer Vision.
What is Kubernetes?
Kubernetes is a big data software created by omnipresent Google and constantly developed. Kubernetes, also known as K8s, can automatically scale instances, verify whether the given containers are working, and, if necessary, destroy faulty ones and create new, healthy containers in their place. The process is called self-healing. In addition, this orchestrator allows for automatic zero downtime, new release deployment, and rollbacks to the previous working app versions.
K8s is widely used by large organizations. Though, it might be too time-consuming and problematic to set up for smaller companies. Hence, the latter most often use a ready-made version of Kubernetes installed in the cloud.
Although Kubernetes consists of many parts, we can distinguish two primary ones:
Control plane: ensures the app is always in the state that meets our intention; there can, or even should be, more than one control plane
Worker nodes: virtual or physical machines responsible for executing containers that, in turn, are placed into pods; there can be one (a recommended option) or more containers in one pod
Kubernetes distributions
We can distinguish various Kubernetes distributions – software packages with prebuilt K8s versions. We’ll explain the six core in short.
K8s
It’s a full version of Kubernetes. K8s allows for numerous modifications, and the sky’s the limit of what it can do. But the truth is, it’s pretty heavy and resource-consuming. We can’t imagine using it anywhere else than in production because of its long-drawn-out setup. Every component has to be picked and installed separately, which takes time. But, of course, the problem doesn’t apply to the cloud K8s version.
K3s
It’s a lighter version of Kubernetes with minimum hardware requirements. All components are bundled into a single binary, which makes it easy to install and configure. It allows you to create clusters that run in a virtual machine (VM) and supports helm chart management. You can use K3s in various environments, particularly in resource-constrained ones like IoT apps or edge devices.
K3d
It is a lightweight wrapper for K3s in Docker instead of VM. It creates multi-node K3s clusters that can be set up on a single machine.
microK8s
MicroK8s allows for a fast Kubernetes installation, with K8s services provided in a single package. It’s known for its low-maintenance and low- or even zero-ops infrastructure. Its lightweight distribution is often used in the cloud, for local builds, and IoT devices.
miniKube
MiniKube is the most popular kind of Kubernetes distribution used for local testing. We use it for local cluster development on a computer or CI rather than on the whole infrastructure.
Kind
Kind is a Kubernetes in Docker. We use the tool for development and testing. Kind works similarly to miniKube; the only difference is that it takes advantage of Docker as cluster nodes.
The table shows our approach to Kubernetes distributions and their uses:
Development only | Development & Production | Production only |
mindKube | K3s | K8s |
Monitoring tools: Prometheus and Grafana
Performance and task monitoring, as well as visualizing, is an integral part of working with high data volumes; for that purpose, we can use ready-made software for big data analytics. The main goal is to examine tasks performed within the pipeline, such as a live preview of the inferences from the ML models, prediction statistics, etc. Secondly, we analyze computer performance in real-time to find possible errors. This way, we can swiftly react with upgrades or extra resources.
We can recommend two tools that do the job and get on pretty well with each other:
Prometheus
Prometheus is a monitoring and alerting toolkit considered a standard for Kubernetes. It collects time-series data, stores it, builds queries, and generates alerts. Custom metrics allow for prediction statistics gathering.
Moreover, cAdvisor and nvidia-smi-exporter can be used for easy export of load metrics like RAM, GPU VRAM, and CPU utilization that can be directly pulled by Prometheus. System overload can be defined based on the aforementioned load metrics and monitored using alerts sent to services like pager duty, gmail, or slack channel. Although Prometheus offers built-in dashboarding, its use is limited. Thus, we prefer to use a more advanced tool, described below.
Grafana
Grafana is a visualization system that creates dashboards based on data collected by Prometheus. It presents information in the form of graphs, charts, heatmaps, tables, and many more (see all visualization options available). You can also share the dashboards with your colleagues and manage user access.
As you can see, the two solutions are essentially complementary. In the most straightforward words, Prometheus collects metrics, and Grafana transforms them into visual representations.

Data management: Apache Cassandra
We’re coming to an end with the subject of data governance. For this purpose, we’ve chosen Cassandra. It is a distributed, multi-node data management system that easily integrates with Spark and various programming languages.
Cassandra has been designed particularly for multiple data center deployments. In Cassandra, all nodes have the same rank; thus, we won’t find a single point of failure (SPOF), which works in favor of the system’s reliability.
Asynchronous replication across multiple data centers translates into low-latency operations, which means an ability to withstand data center outages irrespective of the type of storage you use: a public/private cloud or on-premise infrastructure. Cassandra has been tested on 1,000-node clusters to ensure its stability.
The system has introduced the Cassandra Query Language (CQL), but if you’re familiar with SQL we use to handle data, you shouldn’t worry about CQL use.
Last but not least, here’s the team that worked on our internal project and tested all the big data technologies and tools we explored for you (kudos for your work!):
Daniel Popek, Data Scientist
Paweł Mielniczuk, Data Scientist
Mikołaj Patalan, Machine Learning Researcher
Tomasz Cąkała, Machine Learning Researcher
Jakub Jaszczuk, R&D Software Engineer